The Architecture Graph is a graph modeling technique that uniformly covers
- relational tables,
- views,
- database constraints,
- queries and,
- any kind of attributes
as first class citizens in a data-centric environment.
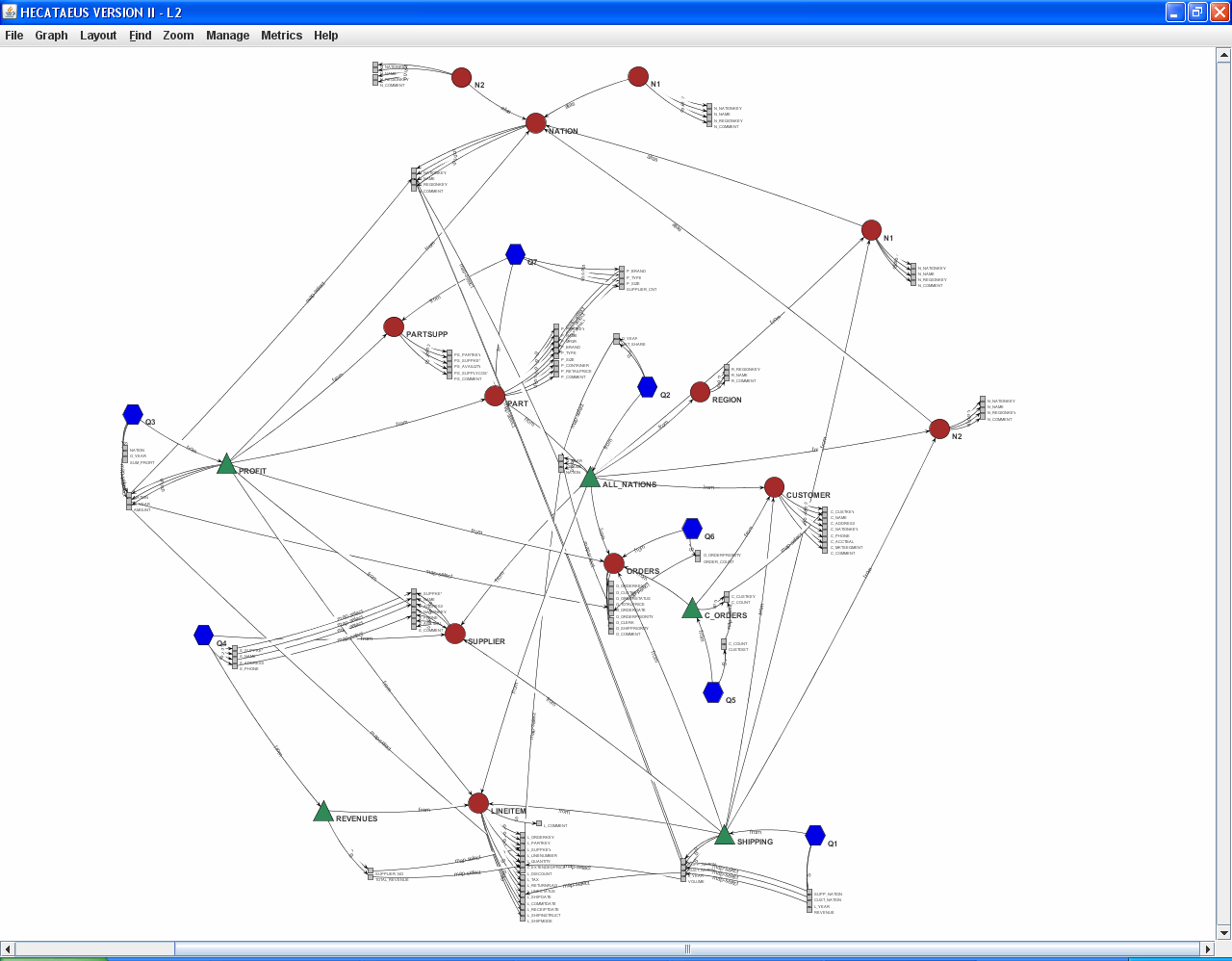
Traditional database modeling techniques, like ER diagrams, UML, etc., have been widely used in modeling database entities and relationships between them. Most of them, however, restrict themselves in explicitly modeling the main database parts (e.g., entities, relationships) of an information system, while ignoring components that interface with the database, such as queries, views, stored procedures, applications, etc. An ER diagram, for example, can describe in a precise way how data is to be stored and treated within a database, but cannot tell what is happening “around” the database in terms of queries, or how information flows through the components that interface with the database. This kind of knowledge is valuable to database administrators and designers, since it can be used for several purposes, including (a) the forecasting of the impact of changes in the system (e.g., what happens if we delete a certain attribute of a table?), (b) the visualization of the workload of the system (e.g., which queries pose the heaviest load on the system?) and (c) the evaluation of the quality of the database design.
The Architecture Graph is a graph modeling technique that uniformly covers |
|
Scripts, software modules, reports and data entry forms can be abstracted as sequences of database queries, as far as the DBMS is considered. Thus, the Architecture Graph provides an overall picture not only for the actual database schema, but also for the architecture of a database system as a whole. The main idea behind the notion of the Architecture Graph is to represent all the aforementioned database parts as a directed graph with the aforementioned entities being represented as nodes and edges covering different semantics of their interrelationships (e.g., part-of, value mapping edges, etc).
Naturally, to deal with the complexity and the sheer volume of the modeled meta-information, the Architecture Graph must be accompanied by appropriate visualization techniques that allow zooming in and out at various levels of detail.
One of the main roles of blueprints is their usage as testbeds for the evaluation of the design of an engineer. In other words, blueprints serve as the modeling tool that provides answers to the questions | 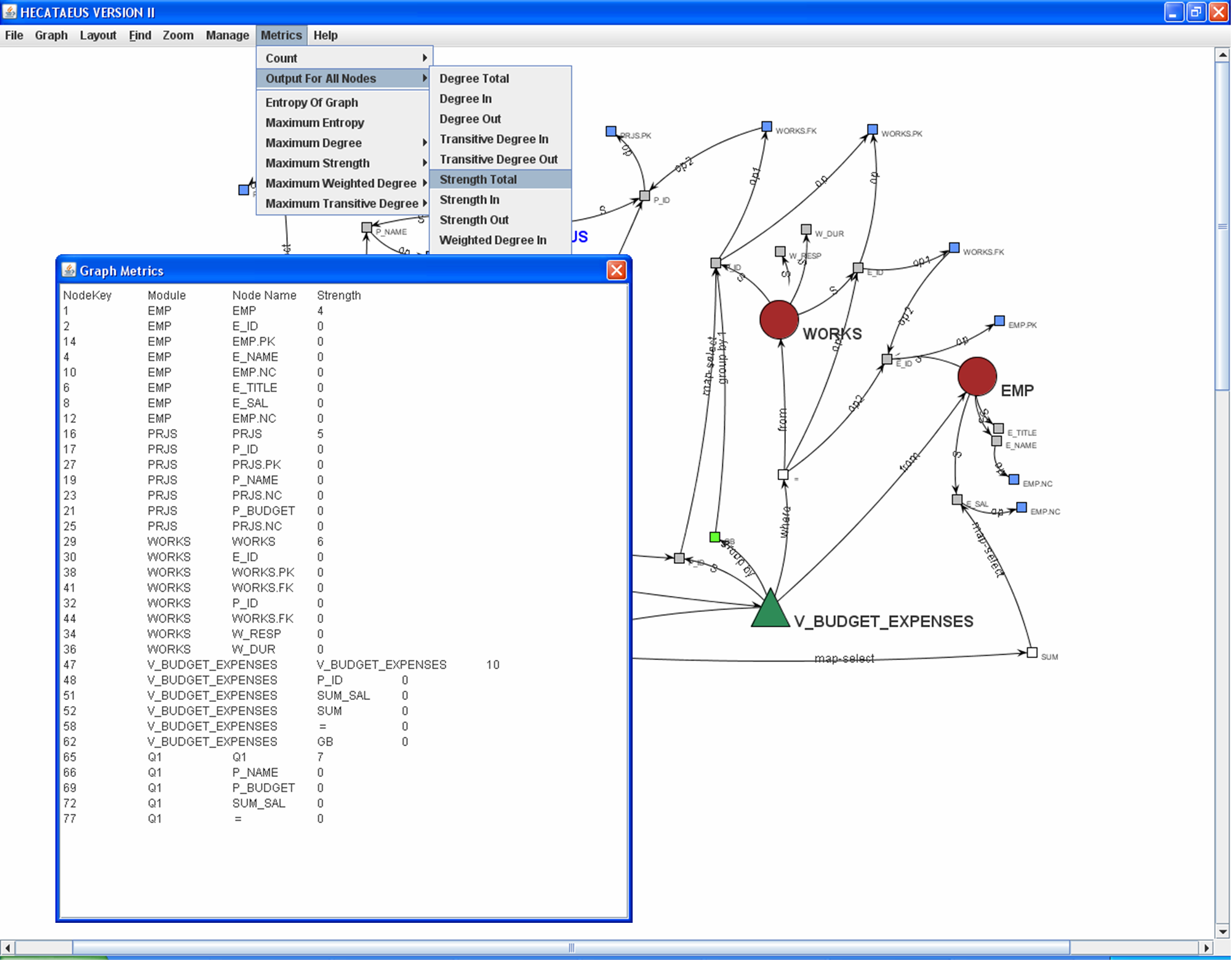
|
There is a huge amount of literature devoted in the evaluation of software artifacts. The main idea for the state-of-the-art in design metrics is the adoption of measure families, like size, complexity, coupling and cohesion for graph-theoretic system representations. The definition of these measure families is generic, in the sense, that depending on the underlying context, one can define his own measures that fit within one of the aforementioned categories. In order to be able to claim fitness within one of the aforementioned categories, there is a specific list of properties that the proposed measure must fulfill.
Our research fundamentally aims in discovering the laws that should govern design metrics for data-centric systems. Our fundamental concern, for defining our measures is the effort required (a) to define and (b) to maintain the Architecture Graph, in the presence of changes. Therefore, the statements that one can make, concerning our measures characterize the effort/impact of these two phases of the software lifecycle.
In typical organizational Information Systems, the designer/administrator is frequently faced with the necessity to predict the impact of a small change in the overall configuration. For instance, assume that an attribute has to be deleted from the underlying database. A small change like this might impact a large number of applications and data stores around the system: queries and data entry forms can be invalidated, application programs might crash (resulting in the overall failure of more complex workflows), and several pages in the corporate Web server may become invisible (i.e., they cannot be generated any more). Syntactic as well as semantic adaptation of queries and views to changes occurring in the database schema is a time-consuming task, treated in most of the cases manually by the administrators.
Our approach, is to provide a general mechanism for performing impact analysis for potential changes of database configurations. |
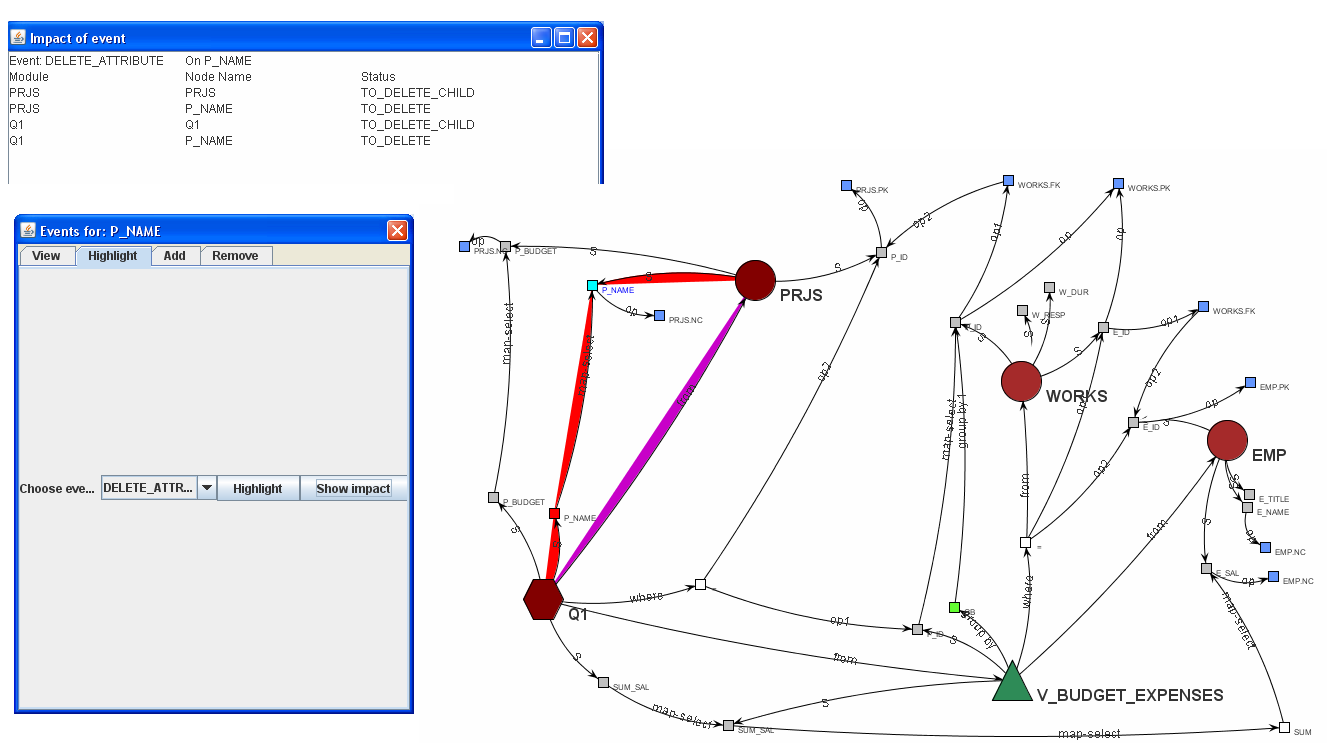 |
Apart from the simple task of capturing the semantics of a database system, the Architecture Graph allows us to predict the impact of a change over the system. To this end, in the context of evolution management, the Architecture Graph must be annotated appropriately with policies concerning the behavior of nodes in the presence of (hypothetical) changes. At the same time, rules that dictate the proper actions, when additions, deletions or updates are performed to relations, attributes and conditions (all treated as first-class citizens of the model) must be provided. In other words, assuming that a graph construct is annotated with a policy for a particular event (e.g., an activity node is tuned to deny deletions of its provider attributes), the proposed framework (a) performs the identification of the affected subgraph and, (b) if the policy is appropriate, automates the readjustment of the graph to fit the new semantics imposed by the change.